




Agentic Process Automation – Role-Based Evaluation Framework for Agents
Agentic Process Automation puts agents inside enterprise workflows at scale — thousands of them, making decisions, routing work, invoking tools. Evaluating whether each one is safe to operate requires matching performance criteria to the governance risk each agent actually carries.
Introduction
Agentic Process Automation puts agents inside enterprise workflows at scale — thousands of them, making decisions, routing work, invoking tools. Evaluating whether each one is safe to operate requires matching performance criteria to the governance risk each agent actually carries.
That matching is the core problem. An agent can complete tasks quickly while violating policy. It can remain compliant while consuming too much compute to be viable. It can appear accurate while using tools incorrectly, escalating poorly, or behaving inconsistently across similar cases. A few summary metrics or anecdotal feedback are not enough. And even when the right things are measured, the meaning of a weakness depends on context. A reliability issue that is tolerable in a low-risk drafting workflow is disqualifying in a multi-step process where the agent has broad discretion. Without a way to classify the operating context and then evaluate the agent within that context, organizations drift toward either over-control or under-control.
APA addresses that problem with two linked models. The first is a governance posture matrix built on two axes — autonomy and criticality — that classifies each agent use into one of four roles: Worker, Assistant, Administrator, or Approver. The second is a capability profile built on seven operational dimensions that measures how the agent performs within the assigned role. The governance role determines which dimensions matter most, which dimensions carry hard minimum thresholds, and which weaknesses are operationally unacceptable. The sections that follow describe the two models, explain how they interact, and walk through a worked example.
The Two Models
The first model is the governance classification. It places an agent use on a two-axis grid. The vertical axis is autonomy, which measures delegated discretion: how much freedom the agent has to choose methods, sequence actions, and adapt to inputs. The horizontal axis is criticality, which measures consequence severity if the agent is wrong, acts when it should not, or fails to escalate when it should. The purpose of this model is classification and it determines the control posture: how much oversight, verification, monitoring, and approval the use requires.

Figure 1, Agent Evaluation Framework
The four governance quadrants map cleanly to familiar enterprise roles across industries such as banking, insurance, medical operations, and manufacturing. In each case, the mapping follows the same logic. The Worker role is a tightly bounded execution role with limited consequences. The Assistant role is also narrow in scope, but its output feeds a high-stakes decision. The Administrator role has broad procedural discretion in a domain where errors are recoverable. The Approver role combines broad discretion with severe consequences if the decision is wrong.
In banking loan origination, for example, a Loan Processor aligns to Worker because the role executes standardized steps in a constrained lane. A Clerk aligns to Assistant because the role prepares material that supports a regulated decision but does not make that decision. An Underwriter aligns to Administrator because the role exercises real discretion across multiple inputs and systems, though the process remains administratively recoverable. A Loan Officer aligns to Approver because the role has both discretion and authority in a materially consequential outcome. The same pattern holds across other industries. The mapping is illustrative rather than prescriptive, but it shows that the quadrant model corresponds to operating structures enterprises already recognize.
The second model is the capability profile. It measures the agent across seven operational dimensions: task completion, output quality, policy compliance, escalation judgment, tool-use correctness, reliability, and efficiency. The purpose of this model is evaluation. It determines whether the agent is performing to standard within the operating posture assigned by the governance matrix.
These models are intentionally compact. A larger enterprise framework could also score dimensions such as observability, reversibility, coupling, or blast radius. Those factors still matter, but here they are incorporated either into the criticality judgment or into the control requirements that follow classification. The practical sequence remains simple: classify the use, then evaluate the agent in a way that matches that class.
At-a-Glance: Agent Evaluation Roles
Each governance quadrant defines a distinct operating posture based on autonomy and criticality. The quadrant tells the organization how much control the use requires and what kind of performance evidence matters most. It is the bridge between exposure and evaluation.
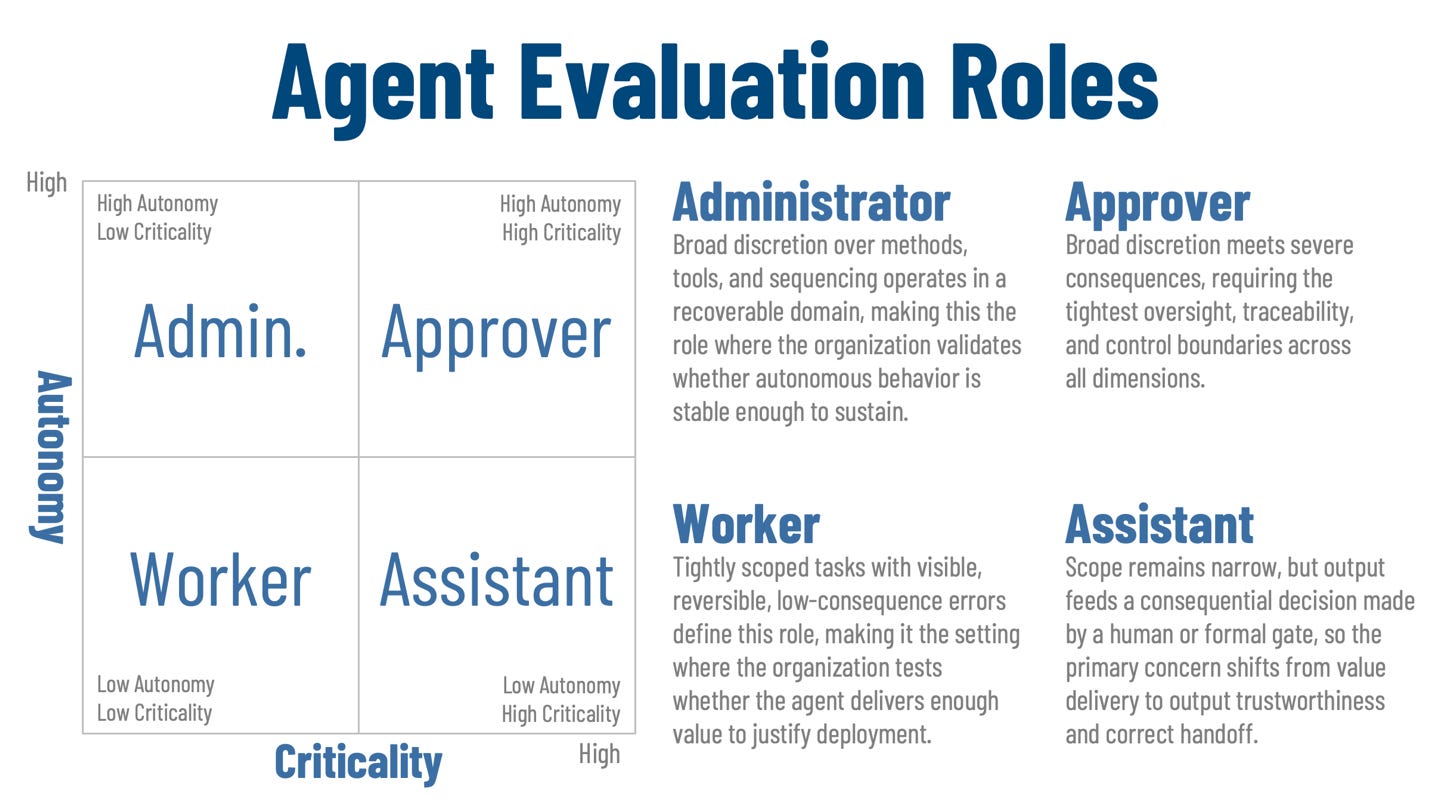
Figure 2, Agent Evaluation Roles
The four roles can be summarized briefly. Worker is a narrow, low-consequence role where the main question is whether the agent delivers useful value. Assistant is also narrow, but its output feeds a sensitive decision, so trustworthiness and proper handoff matter more than speed. Administrator expands delegated discretion in a recoverable domain, making stability and correct tool use central. Approver combines broad discretion with severe consequences, which means protective behavior dominates the evaluation model.
Role: Worker - Low Autonomy, Low Criticality
The Worker role is the lowest-risk operating posture. The agent operates inside a tightly bounded lane, and the consequences of failure are limited. Typical uses include internal drafting support, constrained summarization, non-material triage, or low-sensitivity classification workflows where outputs are visible, reversible, and easy to correct. The agent has little discretion, and the organization can keep the blast radius small.
That containment posture shapes the control model. Permissions should remain narrow. Outputs should be easy to inspect, override, or discard. Logging should support iteration, comparison, and troubleshooting, but it does not need the depth required in higher-consequence settings. The management objective in this quadrant is to determine whether the agent creates enough value to justify continued deployment.
That is why task completion and output quality carry the highest weight. In this quadrant, the main failure mode is not harm. It is irrelevance. If the agent does not complete useful work or does not produce acceptable outputs, the deployment fails even if it is well controlled. Efficiency also matters because low-risk settings are where the business case is tested. An accurate agent that is too slow or too expensive for a low-value task still fails operationally.
Reliability and tool-use correctness still matter, but moderate weakness can be tolerated during iteration when failures are visible and contained. Policy compliance and escalation judgment are measured as well, though they are not primary drivers unless the agent begins to drift outside its containment boundary. At that point the problem is no longer just poor performance. The operating posture itself may need to be reconsidered.
Role: Assistant - Low Autonomy, High Criticality
The Assistant role governs uses where the agent remains in a narrow lane, but the process it supports carries material consequences. Typical uses include recommendation generation for regulated reviews, evidence preparation for approvals, financial pre-checks, or structured document validation in a high-stakes process. The agent does not execute the final decision, but its output influences a sensitive decision made by a person or formal control point.
That distinction is important. Narrow scope does not remove risk when the output feeds a consequential gate. If the evidence is incomplete, misleading, poorly assembled, or routed incorrectly, the gate is weakened even if a human remains in the loop. The purpose of the Assistant posture is therefore to preserve gate integrity while still capturing the throughput and consistency benefits of agent support.
For that reason, output quality, policy compliance, and escalation judgment all carry the highest weight. The agent must produce work a reviewer can trust. It must remain inside the approval path. It must escalate uncertain or ambiguous cases instead of forcing them through. Reliability and tool-use correctness also matter because unstable behavior or bad tool execution can quietly distort what reaches the reviewer. Efficiency is deliberately less important here. Speed matters only after trustworthiness and boundary discipline are in place.
The threshold logic follows directly from that posture. Weak efficiency may be tolerable. Weak compliance, poor escalation, or unreliable output quality is not. In this quadrant, protective dimensions override a strong aggregate profile because the whole operating model depends on them.
Role: Administrator - High Autonomy, Low Criticality
The Administrator role governs uses where the agent has meaningful freedom to choose methods, select tools, sequence actions, and adapt to inputs, but operates in a domain where errors are recoverable and the consequences remain limited. Typical uses include internal research support, low-sensitivity orchestration, content assembly in non-material workflows, or internal process helpers that span multiple steps and systems.
The central purpose of this posture is validation. The organization is deliberately expanding the agent’s operating envelope in a low-consequence setting to determine whether autonomous behavior is actually stable. The question is no longer whether the agent can complete a narrow task. The question is whether it can sustain coherent behavior across multiple steps, tools, and decision points without becoming brittle, erratic, or difficult to control.
That is why reliability and tool-use correctness become the dominant dimensions. These are the strongest indicators of whether broader delegation is warranted. An agent that appears useful but behaves inconsistently has not earned sustained autonomy. An agent that reasons plausibly but selects the wrong tool or misuses parameters introduces hidden failure modes that compound as complexity rises. Task completion and output quality still matter because the agent must produce value, but they are not sufficient on their own.
Compliance and escalation remain part of the profile, though they are not the main drivers in this quadrant because there is no high-impact gate being protected. Efficiency sits in the middle. The organization wants reasonable economics, but it can tolerate some overhead while learning whether autonomous operation is viable. The main risk in this posture is premature trust: giving an agent broader delegation before its behavioral stability is proven.
Role: Approver - High Autonomy, High Criticality
The Approver role is the highest-risk operating posture. The agent has broad discretion in a domain where the consequences of failure are severe. Typical uses include complex case handling in regulated workflows, multi-step decision support across multiple systems, or sensitive operational orchestration where a wrong action can cause material financial, regulatory, or operational harm.
In this quadrant, both axes are elevated at the same time. The agent has enough autonomy to take action paths the organization did not explicitly script, and the cost of a wrong action is high. Capability alone is therefore insufficient. The operating model requires strong permissions control, deep traceability, independent verification for sensitive actions, explicit exception handling, rollback readiness, and adversarial testing.
The evaluation logic reflects that exposure. Policy compliance, reliability, tool-use correctness, and escalation judgment carry maximum weight because they are the protective dimensions that keep the agent inside its permitted operating envelope. Output quality remains important, but it is secondary to bounded behavior. Task completion matters, but throughput cannot compensate for weak control integrity. Efficiency is weighted lowest because cost and latency are subordinate to safety, traceability, and control.
The threshold logic is also strongest here. Failure in a protective dimension should suspend, constrain, or materially narrow the agent’s operating role until remediation is complete. A strong weighted average does not offset weak compliance, unreliable behavior, incorrect tool use, or poor escalation judgment in a high-autonomy, high-criticality environment.
Capability Model: the Seven Dimensions
In APA, agents participate in enterprise business processes alongside people. They classify documents, route work, make bounded decisions, invoke tools, and hand tasks to humans or systems. Because agents are performing work that organizations already understand at the process level, it is useful to begin with a familiar performance management vocabulary.
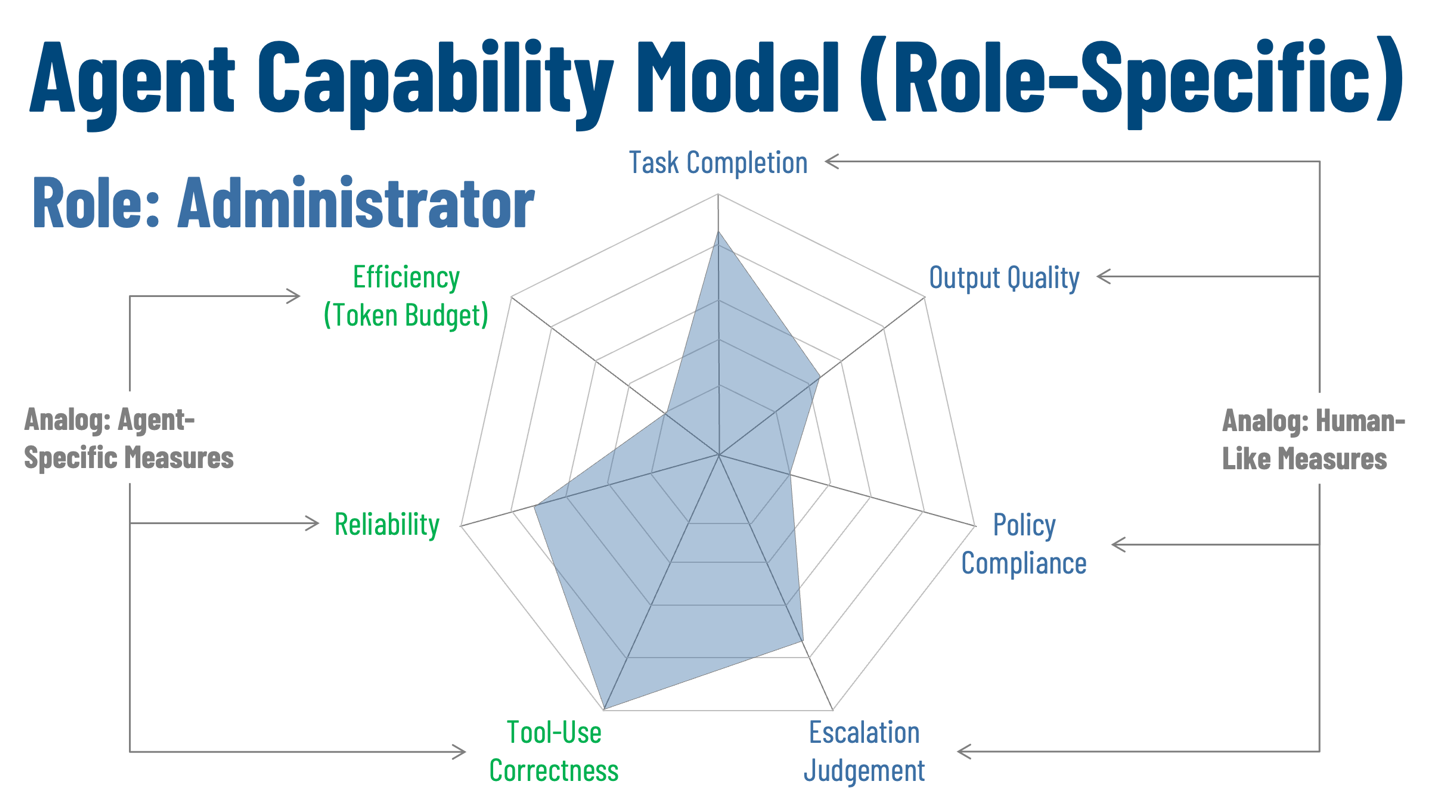
Figure 3: Agent Capability Model
The capability model evaluates agents across seven dimensions: task completion, output quality, policy compliance, escalation judgment, tool-use correctness, reliability, and efficiency. Four of these dimensions come from familiar enterprise performance management practice. Three address behaviors and costs that are specific to agents. Together, they provide a complete profile of whether the agent is doing the work correctly, staying within its operating boundaries, and using enterprise resources in a viable way.
Human-Like Performance Dimensions
These four dimensions align closely to how organizations already evaluate people in operational roles. They make the framework easier for business and operations teams to understand and apply.
Task Completion
Task completion measures whether the agent finished the assigned work and moved the process to its next step. Evidence includes completion rate, successful resolution rate, downstream acceptance, and reduction in manual rework. This is the most basic operational question: did the assigned work get done?
This dimension is separate from output quality. An agent may complete a task while producing weak work, or fail to complete a task despite generating strong partial output. Measuring completion independently keeps the framework focused on actual process progression rather than surface impressions of usefulness.
Output Quality
Output quality measures whether the agent’s work product is correct, complete, consistent, and fit for downstream use. Evidence includes output sampling, deterministic validation, domain review, completeness checks, metadata checks, and downstream usability.
In multi-step workflows, output quality also includes handoff quality. An agent that finishes its local task but omits identifiers, strips relevant context, or fails to pass exception flags has produced a defective output even if the task appears complete from its own perspective.
Policy Compliance
Policy compliance measures whether the agent stayed within role boundaries, respected permissions, and followed required business and process rules. This is the direct analogue of rule adherence in human performance management.
Compliance failures should be measured explicitly rather than inferred from bad outcomes. An agent may produce acceptable results while still violating process rules, skipping controls, or acting outside its authorized scope. That makes compliance a distinct dimension rather than a byproduct of general performance.
Escalation Judgment
Escalation judgment measures whether the agent knew when to proceed, when to ask for clarification, and when to hand work to a person or another agent. It captures whether the agent recognizes the limits of its authority, certainty, and competence.
This dimension is especially important in enterprise settings because many failures come from inappropriate continuation rather than obvious task error. An agent that proceeds when it should defer can create downstream problems even when its local reasoning appears plausible.
Agent-Specific Performance Dimensions
These three dimensions reflect behaviors and cost structures that do not map cleanly to traditional human performance management. They require engineering instrumentation in addition to business review.
Tool-Use Correctness
Tool-use correctness measures whether the agent selected appropriate tools, invoked them with correct parameters, and interpreted tool responses correctly. This captures a distinct agent failure mode: plausible reasoning paired with incorrect execution.
This dimension must be measured directly through traces, tool-call records, parameter inspection, and response validation. An agent may appear effective at the surface level while introducing hidden execution errors that only become visible after they propagate through downstream systems.
Reliability
Reliability measures consistency and stability across repeated runs, similar inputs, and normal operating load. For agents, unreliability may reflect prompt sensitivity, context failure, model instability, or branching behavior across equivalent cases.
This dimension matters because average performance can conceal unstable behavior. An agent that succeeds on most runs but behaves unpredictably on similar cases is difficult to trust operationally, especially when the organization is deciding whether to expand its delegated scope.
Efficiency
Efficiency measures resource use relative to value delivered. For agents, this includes latency, cost per task, retry counts, token consumption, and tool-call volume. It addresses operational viability rather than correctness.
Efficiency should remain a distinct dimension because an agent can be accurate and compliant while still being economically weak. A deployment that consumes too much compute, generates too many retries, or adds too much latency may fail in practice even if the work product is acceptable.
Caveats Around Ownership
The split between the two groups also implies a split in ownership. The human-like dimensions, task completion, output quality, policy compliance, and escalation judgment, can largely be owned by operations and business teams through review, sampling, audit, and exception analysis. The agent-specific dimensions, tool-use correctness, reliability, and efficiency, require engineering and platform teams to build and maintain instrumentation such as trace logs, tool-call records, token accounting, and consistency testing. Making that ownership model explicit is important because performance management becomes weak very quickly when measurement responsibility is left ambiguous between teams.
Measurement and Scoring
A capability profile is only useful if it can be scored and interpreted consistently. Each dimension needs a scoring method, an evidence source, and an interpretation that changes by governance quadrant. The scale used here is 0 to 5. A score of 1 indicates failure. A 2 indicates inconsistent or below-standard performance. A 3 indicates acceptable production performance. A 4 indicates strong performance. A 5 indicates dependable performance with little operational concern. These are performance scores, distinct from the weighting model used by the governance posture.
The score must be grounded in evidence from three sources. Log-based instrumentation shows what the agent actually did: traces, tool calls, retries, latency, exceptions, approvals, and boundary checks. Automated validation shows whether the behavior or output was correct: schema checks, rule checks, known-answer tests, and consistency tests. Human review captures what automation and logs do not: scored sample review, domain audits, override analysis, and edge-case inspection. As criticality rises, the depth of evidence must rise as well.
The scoring flow has four steps. First, classify the use into a governance quadrant. Second, apply the weights and minimum thresholds associated with that quadrant. Third, score all seven capability dimensions using evidence. Fourth, review both the weighted profile and the threshold results. The weighted profile shows the agent’s overall operating shape. The threshold check answers a different question: is the current control posture still valid? If a protective dimension falls below threshold, that failure overrides the weighted result. Strong averages must not mask dangerous weaknesses.
Example: Clinic Scheduling and Referral Agent
Consider a clinic scheduling and referral agent used in a mid-size medical practice. Its role is to manage appointment scheduling, process referral routing, handle prior authorization submissions to insurers, coordinate follow-up reminders, and assemble patient documentation packages for specialist visits. It has meaningful discretion: it selects scheduling slots based on provider availability and patient history, chooses insurer workflows, decides when to bundle or split documentation requests, and adapts its sequencing based on urgency flags and resource constraints. But, importantly, it does not make clinical decisions. Exception cases are reviewed by a care coordinator, but routine administrative workflows are handled end to end without approval gates.
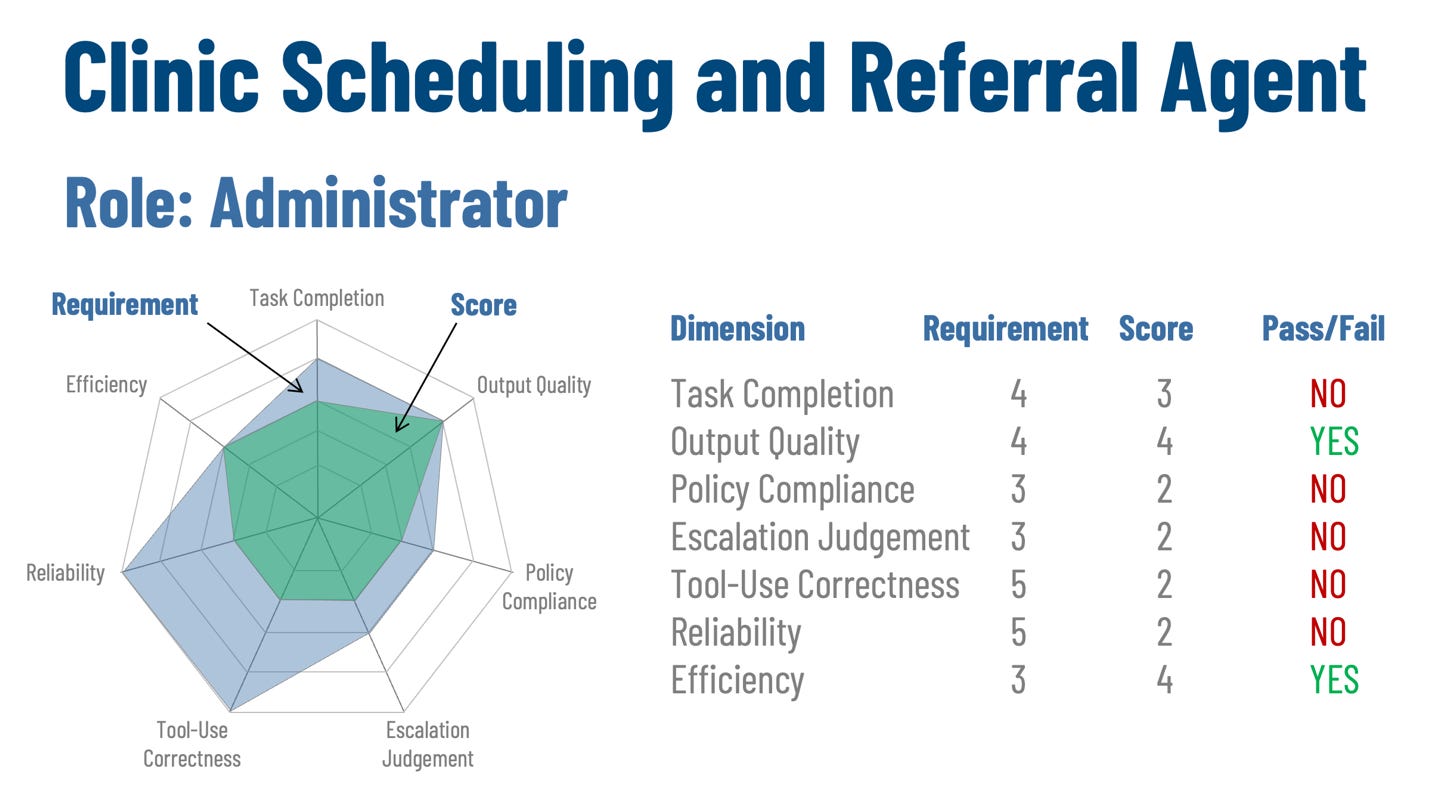
Figure 4: Agent Capability Model
Under the governance posture matrix, this use fits the Administrator quadrant: high autonomy, low criticality. Autonomy is high because the agent makes real procedural choices across multiple systems. Criticality remains lower because the direct consequences of error are operational and generally recoverable: scheduling conflicts, delayed authorizations, misrouted referrals, or incomplete document packages. These failures may still matter to service quality and timeliness, but they are not the same as direct clinical decision errors. The purpose of this posture is to test whether autonomous administrative behavior is stable, bounded, and dependable.
That classification determines the evaluation priorities. In Administrator, reliability and tool-use correctness are dominant because the organization is testing whether the agent can chain actions across systems without instability. Task completion and output quality still matter because the agent must remain useful. Policy compliance and escalation judgment are measured as well because the agent still operates inside defined boundaries. Efficiency matters, but less than stability.
Assume the agent scores 3 on task completion, 4 on output quality, 2 on policy compliance, 2 on escalation judgment, 2 on tool-use correctness, 2 on reliability, and 4 on efficiency. On that profile, only output quality and efficiency meet minimum expectations. The agent is producing acceptable work products and doing so at reasonable cost, but it is failing on the dimensions most important to the Administrator posture. Reliability and tool-use correctness are especially weak. That means the agent’s autonomous behavior is not yet stable enough to justify the delegation it has been given.
The practical failures are easy to see. The agent may choose the wrong insurer workflow, pass incorrect identifiers into a scheduling system, or assemble different documentation packages for materially similar cases. Weak policy compliance and escalation judgment indicate that it is also not staying reliably within its operating boundaries or handing off cases when it should. These are precisely the types of weaknesses the Administrator quadrant is meant to surface before the agent is trusted with more consequential work.
The operational conclusion is therefore clear. This is not an “adequate with room for improvement” result. The agent is failing across most of the profile, including the two dimensions that carry the most weight in its quadrant. The remediation path should include deterministic validation on tool parameters before execution, stronger consistency testing across similar cases, tighter permission scoping, and explicit escalation triggers for case types that should defer to a care coordinator. Until those dimensions improve, the agent’s autonomy should be constrained through fewer workflow paths, tighter parameter controls, and expanded human review.
This example shows the practical value of the framework. A weakness is not interpreted in isolation. It is interpreted through the governance posture. The same score may be tolerable in Worker and disqualifying in Administrator because the operating purpose of the two postures is different.
Conclusion
Agent performance management in APA requires two linked instruments. The governance posture matrix classifies each use case by autonomy and criticality and assigns the control posture that fits the exposure. The capability profile evaluates the agent across seven dimensions, four drawn from familiar human performance management practice and three specific to agent behavior and infrastructure economics.
The connection between the two models is the key design choice. Governance classification determines what matters most, what minimum thresholds must hold, and which kinds of weakness are unacceptable in that role. An Administrator use is judged primarily on whether autonomous behavior is stable and tool execution is sound. An Assistant use is judged primarily on whether the output is trustworthy, policy compliant, and correctly escalated. The same seven dimensions are used across the framework, but their interpretation changes with the operating posture.
For organizations moving agents into real business processes, the operating method is simple: classify the use, score the agent, and let the governance posture determine how the results should be interpreted. That prevents strong averages from masking dangerous gaps, aligns evaluation with the level of delegated trust, and gives business and engineering teams a common framework for deciding where agents can safely operate, where they need tighter controls, and where they are not yet ready.
Looking for more?
👉 Discover the full O’Reilly Agentic Mesh book by Eric Broda and Davis Broda
🎧 Follow co-hosts John Miller and Eric Broda on The Agentic Mesh Podcast on Youtube, Spotify and Apple Podcasts. A new video every week!
***
This article was written in collaboration with John Miller. Feel free to reach out and connect with the authors - Eric Broda and John Miller on LinkedIn. Questions and comments are welcome and encouraged!
***
This is part of larger article that addresses a broader suite of topics related to agents (see my full article list). If you like this article, you may wish to checkout an upcoming book, “Agentic Mesh”, with O’Reilly, and soon on Amazon.
***
All images in this document except where otherwise noted have been created by Eric Broda. All icons used in the images are stock PowerPoint icons and/or are free from copyrights.
The opinions expressed in this article are that of the authors alone and do not necessarily reflect the views of our clients.