




KYA – Know Your Agent
The average enterprise will run more AI agents than employees within three years, but unlike employees, most agents have no verified identity, no access limits, and no audit trail. KYA - “Know Your Agent” applies the same verification and control framework that HR uses for workers - because agents now execute the same business processes employees do.
—
Introduction
Agents will be embedded in business processes with direct impact on operations, data, and compliance. This creates three engineering requirements: limit what the agent can do, record what it did, and explain why it did it.
KYC (Know Your Customer) and KYB (Know Your Business) provide a starting model through verified identity and risk controls. But in enterprises running thousands of agents, knowing your agent—its purpose, policies, and identity—becomes critical.
We think agents will operate more like employees than customers. They need onboarding, access rights, supervision, and review of what they did through audit trails. This means “Know-Your-Agent” (KYA) should follow a “Know-Your-Employee” (KYE) model: least privilege, time-limited permissions, and clear ownership.
This article describes what KYA is and how it works. The goal is to keep agent design simple: agent behavior that is transparent, safe and auditable at scale – we need to know your agent.
KYC, KYB, Welcome to KYA
KYC and KYB exist for a simple reason: when a bank or regulated firm lets someone open an account, move money, or access sensitive services, the firm needs confidence about who is on the other end and what risks they bring. KYC focuses on a person; KYB focuses on a company.
But both are built around the same steps: verify identity, understand risk, apply proportionate controls, and keep evidence that those steps were taken. The goal: reducing predictable failure modes—fraud, misuse, and regulatory breaches—before they happen.
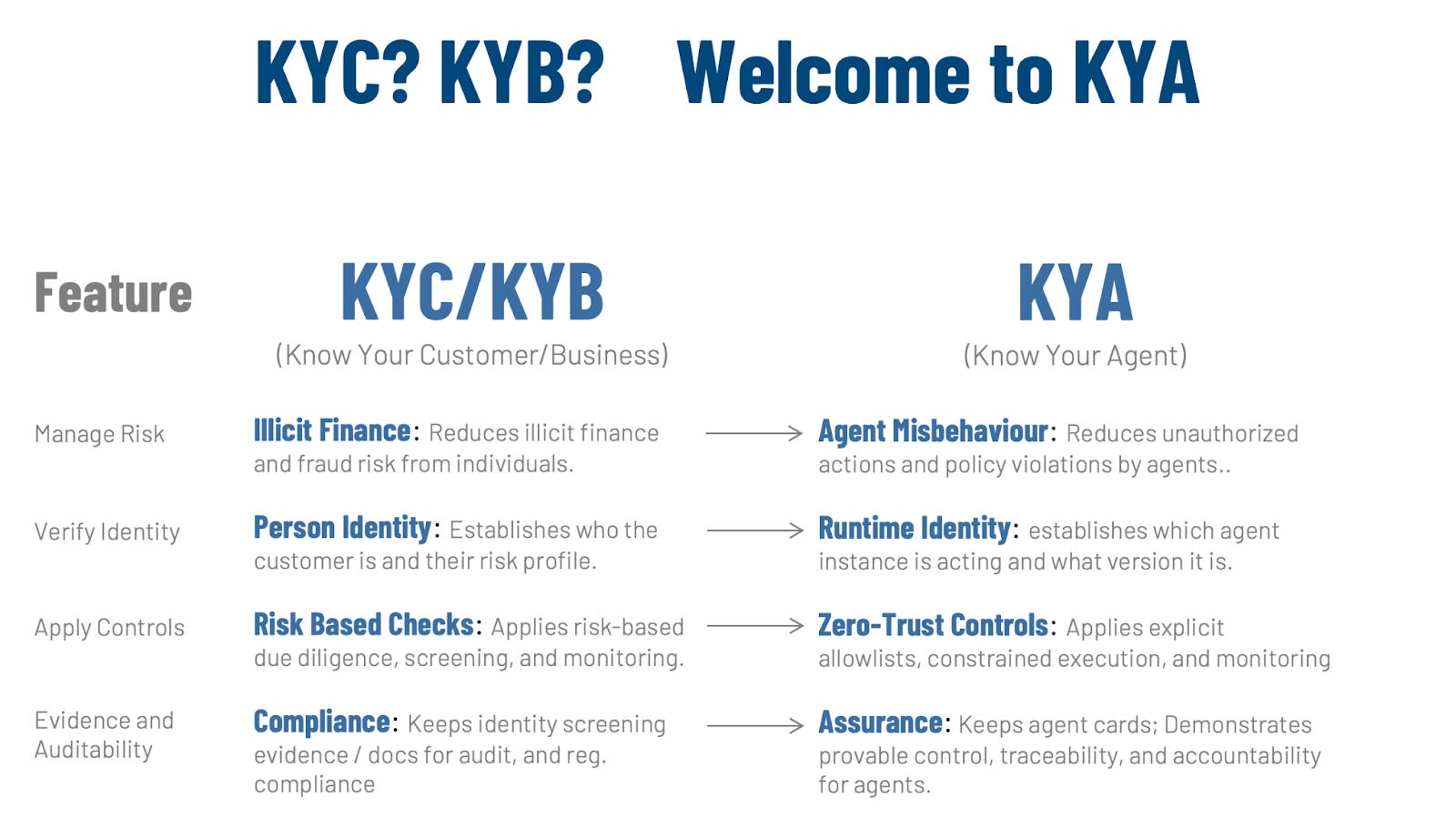
Figure 1: KYC? KYB? Welcome to KYA
Know Your Agent (KYA) applies that same approach to agents that can take actions in business processes. But if an agent can pull data, trigger transactions, send messages, or change records, then “who is acting” matters just as much as it does for a human customer or business.
KYA starts with runtime identity: establishing which agent instance is operating, who owns it, and what version is running, so actions can be tied to a specific, accountable source. It also starts with risk: an agent can make unauthorized or policy-breaking moves because it is misconfigured, overly empowered, or operating on incomplete information.
KYA is also about controls and proof. In KYC/KYB, controls look like screening, due diligence, and monitoring; in KYA, controls look like limiting what the agent is allowed to do and watching what it actually does. The practical goal is to prevent “surprises”: the agent should only be able to use approved capabilities, within clear boundaries, and in ways that can be reviewed after the fact. And like KYC/KYB, KYA requires evidence including records that show what the agent was permitted to do, what it did, and why, so that audits, incident investigations, and reviews can be based on actual facts.
KYA is Built Upon Decades of “Know Your Employee” (HR) Practices
KYC and KYB are definitely useful models, but we think there is an even closer match: agents behave more like workers in your enterprise. We see an employee as an internal actor you onboard, empower, supervise, and hold accountable over time. We think the same applies for agents because they are being asked to participate in real business processes.

Figure 2: Is Know Your Employee (KYE) a Better Model for Agents (KYA)?
The fit is strongest in the way access is granted and controlled. With an employee, you don’t just confirm who they are; you decide what job they are allowed to do and what systems they can touch, and you change that access as responsibilities change. Agents need the same treatment, but tighter. You want a clear record of the agent’s owner and version before it runs, and you want its permissions to be narrow and temporary—activated for a specific task, then removed—because the biggest operational failures come from actors that can do too much for too long.
The same applies to policies and oversight. Human training works because people can be warned, corrected, and slowed down; agents operate at machine speed and will repeat a mistake consistently until something stops them. That means policies have to be enforced by the system and the organization needs a reliable trail of what the agent decided, what tools it used, and what data it touched. When an incident happens, the goal is a factual reconstruction that supports audit, remediation, and recertification. This is why the employee model is more realistic: it treats the agent as an internal operator whose authority must be bounded and whose actions must be reviewable.
Trust in KYA starts with a simple proposition: purpose plus proof. By default, an agent should never be “trusted”. Instead, it should only be trusted when its purpose is clearly and transparently stated and bounded, and because there is concrete evidence it will operate inside those bounds.
In practice, that means you can answer basic questions before the agent runs: what job it is supposed to do, what data and systems can it touch, and what checks prevent it from doing anything else. Addressing a full trust framework is beyond the scope of this article, but we offer a full article that describes this framework (shown in image below) here.
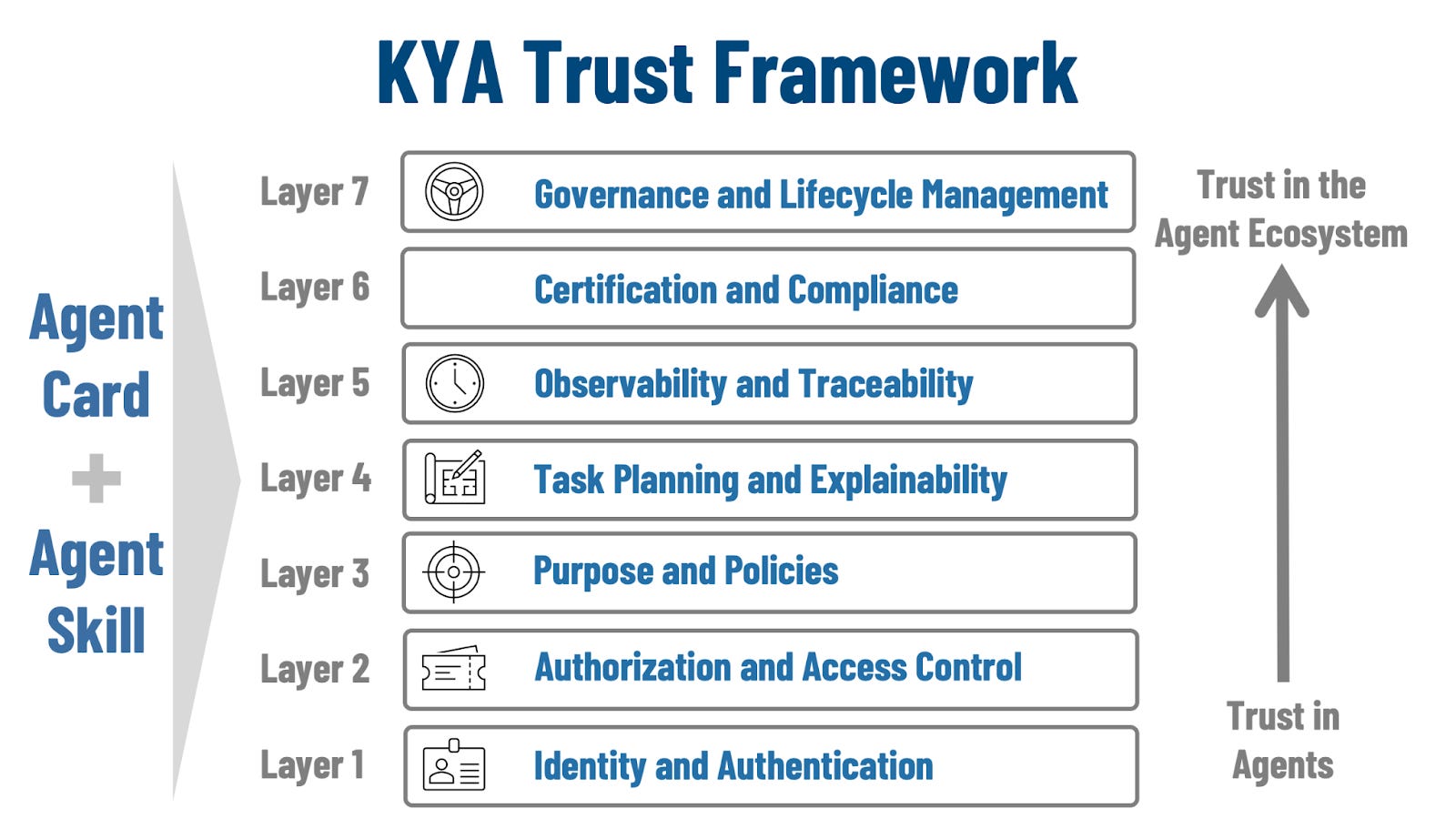
Figure 3: KYA – Fundamental Trust Themes
Second: Trusting a single agent is just not enough; you have to trust the ecosystem the agent lives in. Even a well-designed agent can be pushed into bad outcomes if the surrounding environment is weak. So, there is a real problem if identity can be spoofed, if permissions are too broad, if tool access is uncontrolled, or if actions are not recorded.
The “ecosystem” here is the set of shared services and rules that make agent behavior predictable: authentication, access limits, safe tool interfaces, and an audit trail that lets you reconstruct what happened when something goes wrong.
Third: in world of thousands of agents in any given enterprise, this is a scale problem: trust at scale must be federated. As the number of agents grows, no single team can manually review every agent, every change, and every action. Trust has to be built from repeatable standards that different groups can apply consistently, with shared evidence that can travel across organizational boundaries. That means capabilities that can be applied consistently across an enterprise become critical: common identity and permission models, standard ways to declare purpose and constraints, and consistent logging.
Enterprise Agents vs Coding Agents
Coding agents are taking the software engineering world by storm. So, we would be remiss in not explaining where they fit in KYA (spoiler alert: there is overlap, but also some very specific differences).
Coding agents are built to help an individual or a small team produce software faster: write a function, refactor a module, generate tests, explain an error, or draft a PR description. Their value is local and their blast radius is usually bounded by the developer workflow. Even when they make mistakes, the failure mode is often visible quickly—code doesn’t compile, tests fail, a reviewer catches the issue, or the change never ships. In practice, coding agents live inside a culture and toolchain designed to absorb iteration: version control, CI, peer review, and staged deployment. That scaffolding does not eliminate risk; Instead it narrows the consequences and creates natural checkpoints.
Enterprise agents operate in a different environment. They sit closer to business processes than to code, and they tend to cross boundaries: data domains, systems of record, teams, jurisdictions, and approval chains. Their outputs can become actions that, for example, open accounts, issue refunds, update customer records, route shipments, or generate filings. That makes the critical question about whether the organization can constrain it, attribute its actions, and explain its decisions to auditors, customers, and regulators.
This is one reason KYA matters so much for enterprises. Coding agents can often be made “safe enough” through developer guardrails and human review because the workflow already assumes trial and correction. Enterprise agents, by contrast, must be governable in the way regulated processes are governable: identity that holds up under scrutiny, explicit authorization, clear purpose and decision boundaries, traceability of actions and evidence, and lifecycle controls that prevent silent drift. If agents are becoming operational actors inside the business, then KYA bridges capability and risk.
Lessons Learned
KYC and KYB are useful starting points because they teach the right instinct: if something can touch money, customers, or regulated data, you need verified identity, risk controls, and audit-ready evidence. But agents behave less like external customers and more like internal operators, which makes KYE the closer model: onboarding, scoped access, time-boxed privileges, enforced rules, supervision, and accountability. If you treat agents like employees rather than customers, you naturally design for controlled authority and traceable actions instead of one-time screening at the boundary.
Why This Matters
KYA matters because agents participate fully in business processes, and, soon, at scale a small mistake becomes a large incident. When thousands of agents can touch data, tools, and workflows, the blast radius is no longer a single bad output; it is unauthorized actions repeated quickly across many systems. KYA is the discipline that keeps that authority bounded and accountable. Still, we can learn from decades of experience managing employees. We see KYE – Know Your Employee – practices as the ideal starting point for an kickstarting and enterprise’s KYA journey.
Conclusion
KYA is the practical work of making agents safe to run inside real systems. It starts with knowing exactly which agent is acting, what it is allowed to touch, and what rules it must follow, and it ends with being able to reconstruct outcomes from evidence rather than recollection. In that sense, KYA is less about model capability and more about operational design: narrow permissions, clear purpose, enforced constraints, and records that make behavior reviewable. If those elements are missing, the organization is relying on luck; if they are present, the organization can expand agent responsibility with measured risk.
The near-term reality is that scale will arrive first when a few high-value agents will be deployed broadly, then reused and copied until the fleet grows faster than governance. The real issue is that agents likely will quietly accumulate authority and scale through the most natural of motivations: convenience. The engineering response is to treat every new agent, tool, and version change as a change in operational risk, and to make that risk legible and bounded before the fleet becomes too large to reason about.
This article was written in collaboration with John Miller. Feel free to reach out and connect with the authors - Eric Broda and John Miller on LinkedIn or respond to this article. Questions and comments are welcome and encouraged!
Looking for more?
👉 Discover the full O’Reilly Agentic Mesh book by Eric Broda and Davis Broda
🎧 Follow co-hosts John Miller and Eric Broda on The Agentic Mesh Podcast on Youtube, Spotify and Apple Podcasts. A new video every week!
***
All images in this document except where otherwise noted have been created by Eric Broda. All icons used in the images are stock PowerPoint icons and/or are free from copyrights.
The opinions expressed in this article are that of the authors alone and do not necessarily reflect the views of our clients.
Ah transperancy, recordability, traceability, audability.