




Agentic Process Automation: Next Generation Process Management
Today, business processes powered by RPA and BPA are brittle, constrained by ambiguity, edge cases and inconsistent data formats. Agentic Process Automation lets agents operate as full participants in business processes, executing bounded work under guardrails to fill the process whitespace between SaaS platforms.
—
Introduction
Most enterprise process automation disappoints because real business work is messy: it crosses siloed systems, depends on judgment, and breaks whenever policies, data formats, or exceptions change.
Agentic Process Automation (APA) is a new way of automating business processes using modern agents. APA new control model that preserves and build upon governed process flows, its stages, SLAs, approvals, and audit requirements, but instead moves detailed execution planning into runtime, where agents operate as bounded participants under explicit policy, identity, and tooling constraints.
APA is based upon a foundation of:
Explicit knowledge engineering using structured process knowledge, rules, and context artifacts)
A managed ecosystem of specialized agents with stable identity, naming, OAuth2/RBAC, secure communications, and full traceability, which we call Agentic Mesh
Well defined and reusable skills (based upon “skill.md”, a skill is a small, packaged unit of execution capability that an agent can reliably invoke to do a specific kind of work)
Standards such as A2A, MCP
In this article, we show how APA, backed by an standards-based and skills aware agentic mesh and explicit knowledge engineering, can plan, coordinate, and verify end-to-end execution while remaining auditable and safe.
Agentic Process Automation
Agentic Process Automation (APA): a standards-based approach to business process automation in which governed AI agents use explicit knowledge artifacts to plan, coordinate, and execute multi-step work across people and systems.
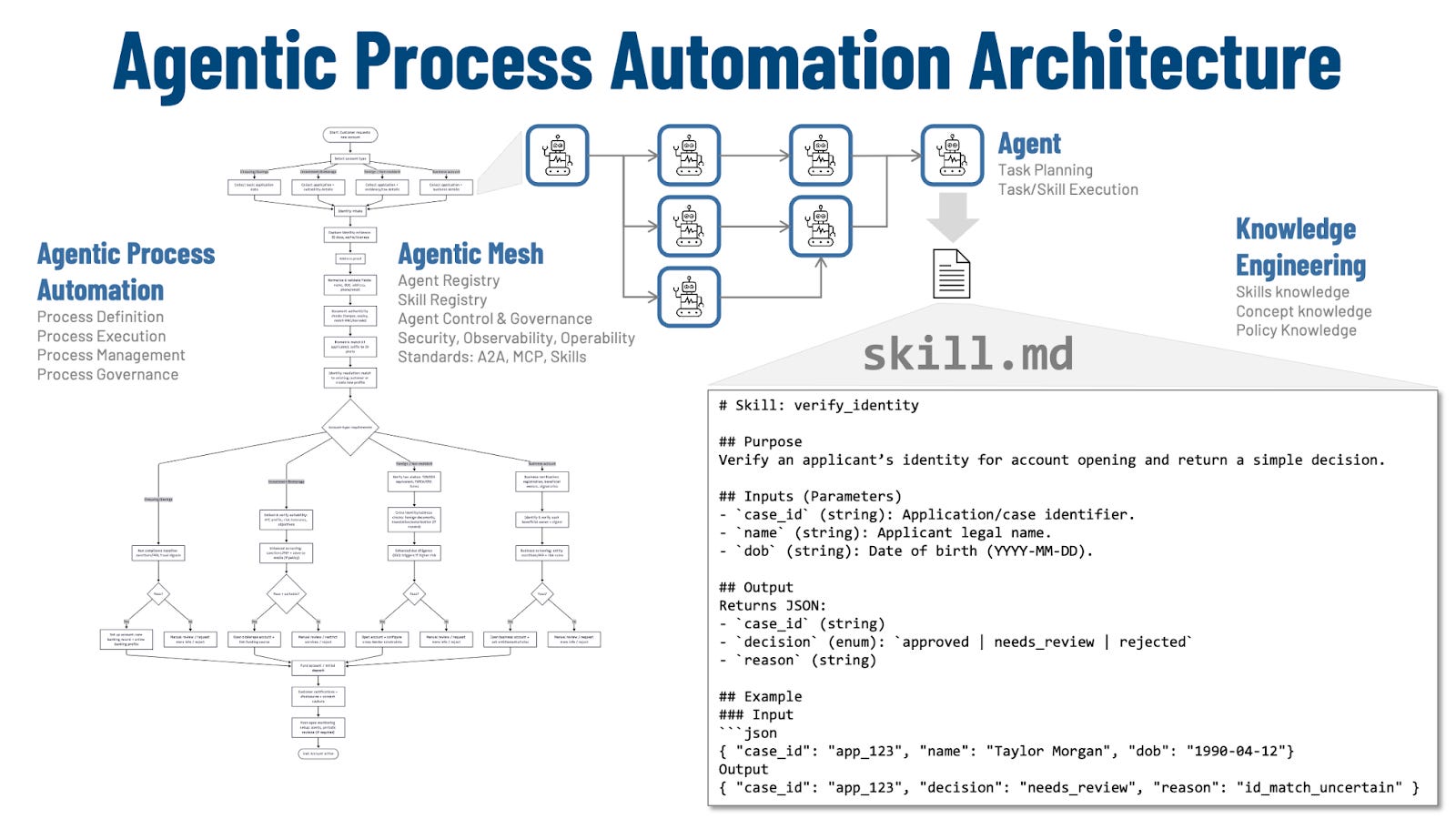
Figure 1: Agentic Process Automation Architecture
Agentic Process Automation is the process manager. It is where an organization defines its process stages, what “done” means at each stage, the required evidence, the approvals, the SLAs, and the audit record that must exist when the work moves forward. APA does not remove structure; it makes the structure executable by agents.
Within that process layer, agents do the work. An agent receives a case, interprets inputs, plans the next steps, and then executes them by calling the right tools and producing the required outputs. Different agents can own different work units such as intake, identity, KYC, provisioning so the end-to-end flow advances through clean handoffs with a structured state update rather than informal, brittle coordination.
APA relies on knowledge engineering to make that agent execution reliable. The “knowledge artifacts” are structured process knowledge: concepts and definitions, policies, rules and decision boundaries, and the minimum context required to perform a stage correctly. This is the prerequisite for consistent behavior: it tells the agent what counts as acceptable evidence, which policies apply, what exceptions exist, and what output format is required so downstream stages and reviewers can trust the result.
That execution runs inside a managed ecosystem we call Agentic Mesh. The mesh provides stable agent identity and naming, secure communications, and governed access to enterprise systems via OAuth2 and RBAC, so agents can only do what they are allowed to do. It also provides durability and traceability: work can be long-running, state can be preserved across steps, and every action can be reconstructed with “who did what, using which tool, under which policy.”
Agents invoke skills which are small, reusable units of execution that do one kind of work predictably, such as verifying an identity, screening a name, or creating an account record. Skills are the bridge between abstract process intent and concrete execution, and they are the main mechanism for reusing process knowledge across products, channels, and regions.
A “skill.md” file is the contract for one of those skills. It states what the skill is for, what inputs it expects, what outputs it must produce, and the constraints it must follow, so an agent can call it reliably and auditors can understand what it did. The result is repeatability: the same skill can be used in many processes, and improvements land in one place instead of being re-implemented repeatedly.
Last but definitely not least, APA becomes easier to scale when it leans on standards. A2A standardizes how agents exchange tasks, messages, and state across boundaries, while MCP standardizes how agents connect to tools and data sources. Together, these standards reduce bespoke integration work, increase portability, and make it practical to build a library of skills and governed agents that can be composed into many processes without rebuilding the plumbing each time.
Filling the Whitespace Between SaaS Platforms
Enterprise SaaS platforms like Salesforce, ServiceNow, Workday, and SAP cover the standardized slices of work that most organizations share. They excel at common support functions—tickets, HR workflows, CRM records, finance transactions—and taken together they account for roughly 20% of total business process value.
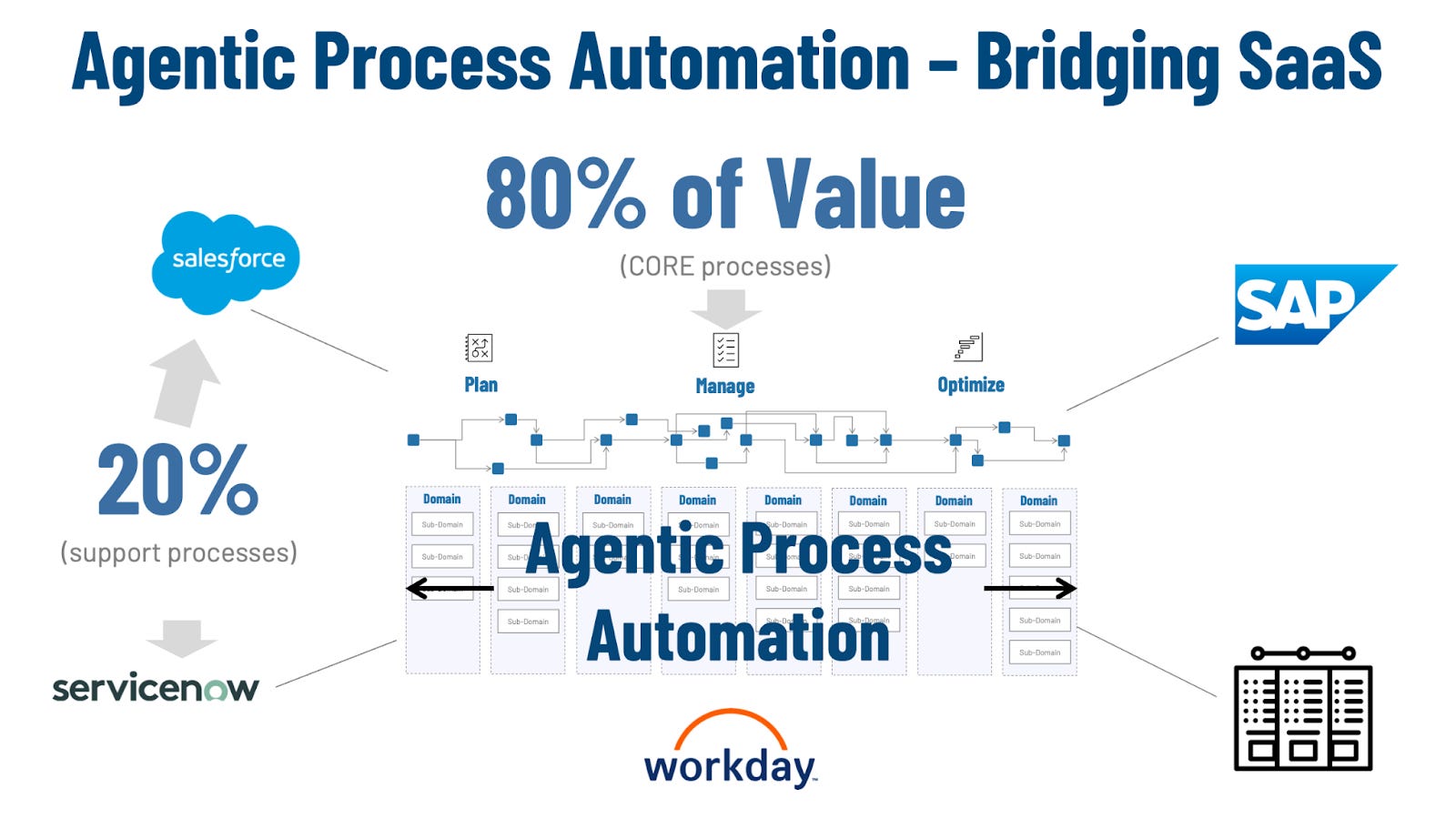
Figure 2 – Agentic Process Automation – Bridging SaaS
The remaining 80% of value is the work that makes a company itself: the cross-functional, policy-heavy, exception-prone processes that span multiple systems, teams, and vendors. This is where competitive advantage lives—how a firm sells, serves, fulfills, manages risk, and adapts to regulation or market shifts. It is also the “whitespace” between SaaS platforms, where organizations end up building bespoke connectors, handoffs, and glue logic to make end-to-end processes actually run.
Agentic Process Automation is aimed squarely at that 80%. Instead of treating each SaaS system as a silo, APA provides the execution layer that plans, coordinates, and moves work across them—using governed agents and explicit process knowledge to keep the process coherent from intake to completion. The result is that the unique, high-value work becomes easier to automate and improve, without having to rebuild the surrounding SaaS landscape.
Enabler: Knowledge Engineering
Knowledge engineering functions as the translation layer between enterprise reality and agent execution. The raw inputs that govern a business process are distributed across structured systems—CRM, ERP, service platforms, data catalogs, and semantic layers—and across unstructured or tacit sources such as SOPs, tickets, chat threads, emails, recordings, regulatory guidance, and expert interviews. These sources contain the definitions, constraints, and operational “gotchas” that determine whether a process is safe and compliant, but they are not organized in a form that an agent can reliably consume at runtime.
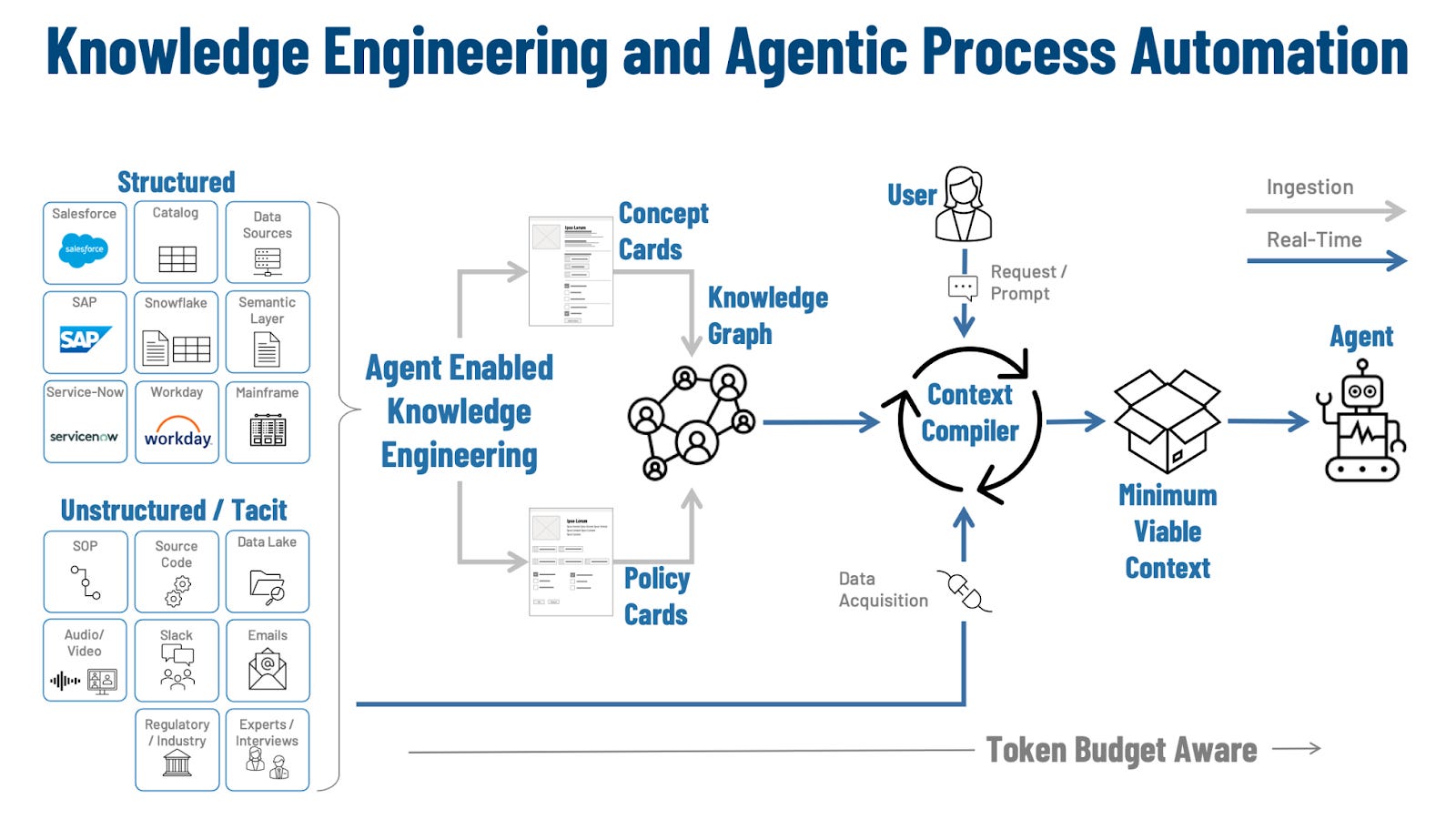
Figure 3: Knowledge Engineering and Agentic Process Automation
Agent-enabled knowledge engineering becomes a key enabler of Agentic Process Automation by turning “filling the context window” into an engineering discipline. Instead of treating context as an ad hoc prompt-building exercise, it defines how enterprise knowledge is captured, normalized, and packaged so agents can execute bounded work in a repeatable way. The objective is operational: produce Minimum Viable Context (MVC) that is sufficient for safe execution while remaining constrained enough to be stable under scale, change, and token limits.
Agent-enabled knowledge engineering converts the sprawl of enterprise knowledge into modular, testable artifacts designed for compilation. Concept Cards represent the stable meaning of the domain: entities, attributes, allowable states, canonical identifiers, reference data, and the relationships that support consistent interpretation across teams and systems. Policy Cards represent enforceable constraints: decision boundaries, required evidence, escalation triggers, approval requirements, and prohibitions tied to specific contexts. In APA terms, these artifacts supply the “what things mean” and “what rules apply” substrate that allows an agent to plan within guardrails rather than improvising from loosely related documents.
Those cards are then connected through a knowledge graph that functions as the semantic backbone for APA execution. The graph is an addressability and linkage layer that connects concepts to the policies that govern them and binds both back to their authoritative sources. This structure constrains retrieval and reduces ambiguity: identity concepts link to verification policies, risk entities link to escalation rules, and every linkage carries provenance. In practice, the knowledge graph is what makes MVC assembly tractable, because it provides deterministic pathways for selecting the right concepts and policies for a given stage without scanning the entire corpus.
At runtime, a context compiler acts as the control plane that converts this engineered knowledge base into an actionable MVC for the agent. A request—initiated by a user prompt or a system event—becomes an input to compilation, and the compiler selects and assembles the smallest set of concept and policy cards required to interpret the case correctly, execute permitted actions, and satisfy audit requirements. This compilation step is the APA hinge: it makes context delivery systematic and repeatable, which is a prerequisite for predictable behavior across many agents, many cases, and many process stages.
The compilation step also enforces the separation between durable knowledge and real-time facts, which is essential for APA in production settings. Definitions, policies, and procedures change, but on slower cadences than case evidence, account state, vendor responses, and risk signals. The compiler therefore pairs curated knowledge artifacts with targeted data acquisition, pulling only the required evidence to resolve the current task. This is where token budget awareness becomes an engineering constraint rather than a limitation: modularization (cards), linkage (graph), and selective assembly (compiler) ensure the agent receives bounded, policy-aligned context, allowing APA to scale without turning the context window into an uncontrolled dumping ground.
Enabler: Agentic Mesh
Agentic Process Automation requires more than capable agents. It requires an operating environment that makes agent plans safe, coherent, and operable when execution spans many stages, many tools, and many long-running cases. That environment is the enterprise-grade agent ecosystem: a shared layer that supplies stable primitives for identity, communication, control, and traceability so agent behavior remains bounded and repeatable under real-world variability.
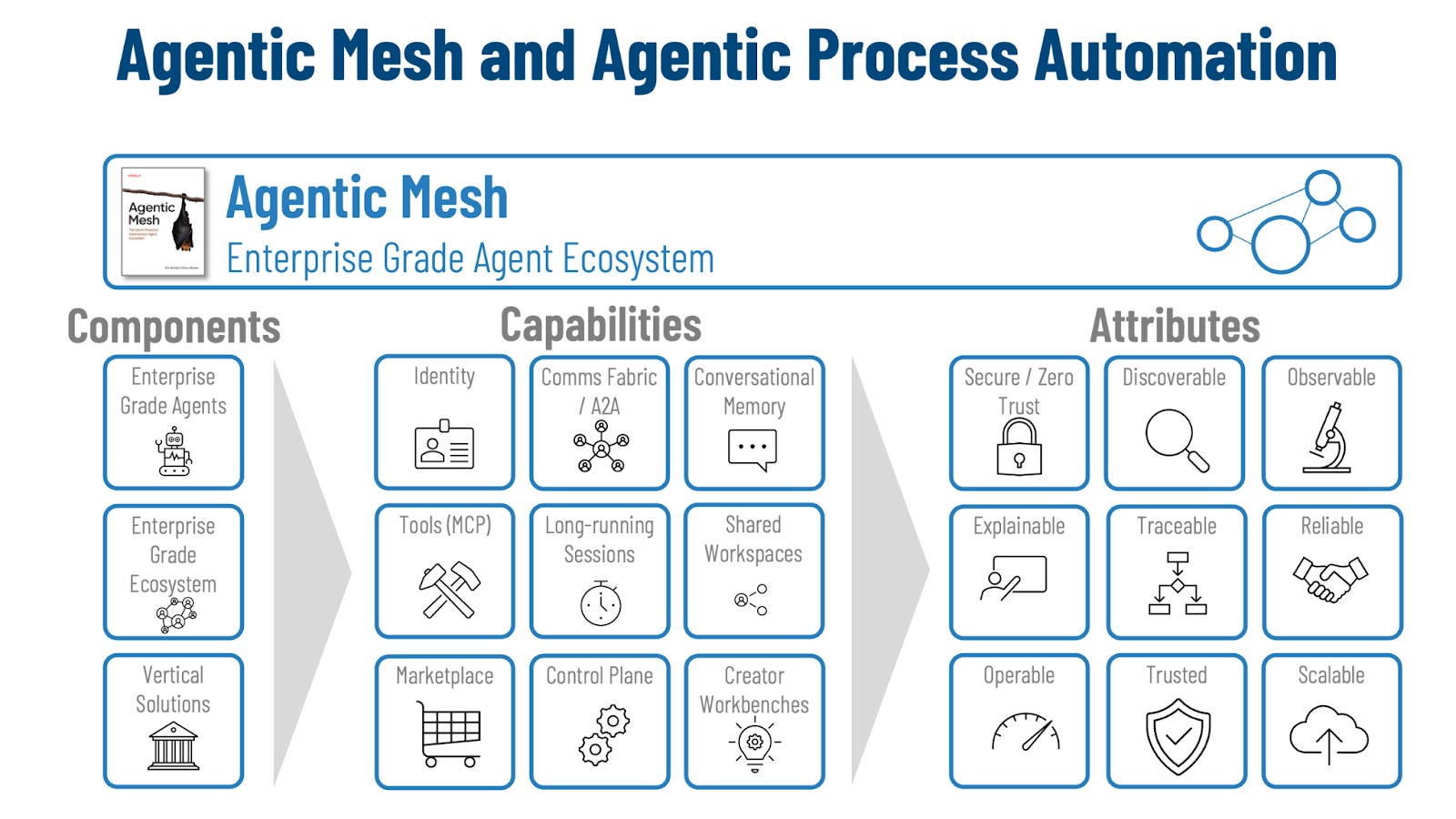
Figure 4: Agentic Mesh and Agentic Process Automation
The ecosystem is built from three distinct layers, each with a different job. Enterprise-grade agents are the workers: they execute bounded units of work, produce artifacts, and drive cases forward. The ecosystem layer is the common substrate that provides common services required by every agent, standardizing naming, interaction patterns, policy enforcement, and lifecycle management. Vertical solutions become domain packages such as banking onboarding, claims, procurement where the specialized semantics and procedures vary, while the underlying rails remain consistent.
The capability set starts with the basics of distributed coordination: who is acting, and how they talk. Identity turns every agent and user into a first-class principal with stable identifiers that survive environments and show up uniformly in logs, permissions, and audit trails. A communications fabric provides the interaction backbone—requests, delegation, events, and status streams—so multi-agent work behaves like one system instead of a collection of point-to-point integrations. With A2A-style normalization, “task,” “status,” and “error” retain the same meaning even when transports differ.
Execution depends on controlled access to tools and durable state, so the next capabilities focus on how work touches the enterprise and persists. Tooling interfaces (such as MCP-style contracts) provide a governed bridge into systems of record, with explicit scopes and enforceable boundaries around what an agent may call and what evidence it must attach. Long-running sessions and conversational memory support the operational reality of approvals, timeouts, retries, and resumable progress. Shared workspaces act as the durable case file: evidence bundles, decision packets, and intermediate state remain available across handoffs and restarts.
Scaling also requires an engineering surface that makes the ecosystem buildable, repeatable, and maintainable. A marketplace makes capabilities discoverable so teams reuse agents and tools instead of cloning patterns and hard-coding endpoints. A control plane provides fleet-level governance—deployment, configuration, policy distribution, and runtime posture—so the platform can be operated with consistent controls. Creator workbenches close the loop by providing the build/test/observe cycle agents require, treating them as software components with instrumentation, test harnesses, and versioned releases.
Those capabilities exist to deliver enterprise attributes that are evaluated in production, not in demos. Secure and zero-trust operation means every action is bound to an authenticated identity and constrained by least-privilege authorization, with enforcement at the platform boundary rather than in handwritten conventions. The result is predictable constraint: even if an agent misinterprets intent, the allowed action space remains narrow, observable, and revocable.
Visibility and accountability form the next set of attributes because enterprises need to manage agents as operational assets. Discoverability ensures agents, tools, and their contracts can be found and understood as part of a catalog rather than tribal knowledge. Observability provides measurable signals across execution—latency, error rates, throughput, and failure modes—so operations teams can detect drift and regressions. Explainability and traceability add the forensic layer, enabling reconstruction across agents and tools: which principal acted, what evidence was used, which policy boundary governed the step, and what side effects occurred.
The final attributes describe whether the system holds up under load and failure. Reliability is defined as correctness under partial failure: durable task semantics, safe retries, and resumable execution that avoids duplicate side effects. Operability means the ecosystem can be controlled at fleet scale through standardized telemetry and consistent management surfaces. Trust and scalability emerge when these guarantees remain intact as the number of agents and processes grows—so adoption increases throughput and coverage rather than increasing integration debt and control risk.
Now, all of this may seem overwhelming or complicated – the truth is that each of these components, capabilities, and attributes are useful but not mandatory. You need to pick what is important to your enterprise’s risk appetite.
Example: Bank Account Open Process
Bank account opening is a useful reference process because it looks linear at the surface, yet it is implemented as a chain of interpretation-heavy stages that span multiple systems, policies, and evidence types. APA succeeds here when the work is made explicit and reusable: knowledge engineering captures the concepts, rules, decision boundaries, and evidence requirements for each stage, and packages repeatable actions as well-defined skills that agents can invoke reliably. Under the hood, the agents operate inside a lightly managed mesh—stable identity, governed tool access, durable workspace state, long-running task handling, and traceability—so each stage can be executed as a bounded work unit: the agent receives the minimum context it needs, calls the right skills, gathers required facts, takes permitted actions, and produces an auditable case packet for downstream stages.
Application Intake
Intake becomes a normalization and case-construction step, where an intake agent converts mixed-format inputs—forms, attachments, free text, and external documents—into a structured dossier with provenance. Knowledge engineering provides the intake ontology (field definitions, document types, validation rules) and the intake policies (what is mandatory, what can be deferred, what triggers escalation). Those requirements are expressed through skills so the agent is executing a known playbook rather than inventing a method. The mesh layer adds the basics that make this safe and repeatable: authenticated access to source systems and document services, a shared workspace to hold the evolving case packet, and traceable outputs that distinguish what was provided, what was inferred, and what remains unknown.
Identity Verification
Identity verification is treated as evidence assembly under explicit decision boundaries rather than a single pass/fail event. Knowledge engineering defines identity concepts (name/address normalization, acceptable ID types, matching tolerances, jurisdiction-specific rules) and the policies that govern what evidence is sufficient and when uncertainty must be escalated. The agent then applies those requirements via a small set of skills—“verify_id_document,” “resolve_identity_record,” “reconcile_mismatches,” “request_additional_evidence”—each producing structured results that can be reviewed. The mesh layer provides governed calls to internal records and third-party verification services, durable storage of artifacts and outcomes in the workspace, and traceability that ties each reconciliation step back to the evidence and policy that justified it.
KYC Processing
KYC processing becomes a policy-governed investigation that turns noisy signals into structured decisions. Knowledge engineering supplies the semantic layer for entities, watchlist concepts, risk factors, thresholds, and required documentation, along with the due diligence rules that determine what must be checked and what triggers escalation. Those checks are executed through reusable skills so the same logic can be applied consistently across products and channels. The mesh layer keeps the work coherent across vendors and internal systems, preserves the evidence and rationale in a durable case record, and ensures the final output is audit-ready without reconstructing the story from scattered logs.
Account Setup and Initial Deposit
Provisioning and initial funding are tool-driven tasks with bounded recovery behavior and durable state. Knowledge engineering defines the procedural requirements (product configuration, required fields, funding rails, holds, constraints by channel) and the decision boundaries that govern retries, fallbacks, and approvals. Skills encapsulate those steps so they are repeatable and testable. The mesh layer contributes least-privilege access to core systems, long-running task semantics for timeouts and partial completion, and a workspace-backed execution record that captures what was attempted, what succeeded, what failed, and what pending state or compensating action remains.
Notifications, Statements, and Ongoing Servicing
Ongoing servicing is handled as constrained, policy-aware interaction tied to a durable case state rather than isolated messages. Knowledge engineering defines service intents, permitted actions, and the policies that govern what can be done self-service, what requires approval, and what triggers risk review, plus the evidence needed to complete common requests. Skills provide consistent execution paths across channels and teams. The mesh layer provides authenticated communication channels, governed tool access for updates, resumable workspace context so conversations and cases don’t fragment, and traceability that records what was communicated, what was changed, and which policy boundary authorized the action.
Lessons Learned
APA rises or falls on knowledge engineering, because knowledge is the fuel that turns “agent autonomy” into reliable execution. When concepts, policies, procedures, and evidence requirements are captured as modular artifacts—definitions that don’t drift, decision boundaries that are explicit, and provenance that is preserved—agents can plan and act with discipline rather than improvisation. In practice, this is what makes Minimum Viable Context (MVC) real: a context compiler can assemble the smallest set of concept and policy cards needed for a specific stage and case posture, so the agent consistently interprets inputs, gathers the right evidence, and produces outputs that map cleanly to audit and control requirements.
APA thrives when it is built on standards, because standards turn one-off integrations into reusable capabilities. A shared interaction model for agent-to-agent and agent-to-tool work—paired with consistent identity, authorization, and message semantics—reduces friction at every handoff: fewer bespoke adapters, fewer edge-condition misunderstandings, and fewer “special cases” that quietly multiply over time. The payoff is both efficiency and effectiveness: efficiency because teams can compose and reuse agents, tools, and knowledge artifacts across processes, and effectiveness because outcomes become more consistent, traceable, and improvable as policies and knowledge evolve without forcing a redesign of the entire automation.
Why This Matters
APA matters because it turns automation into a repeatable operating capability rather than a one-off project. When agents can interpret intent, assemble the right knowledge, and execute across systems under clear policies, organizations stop treating each workflow as bespoke engineering and start treating execution as composition. That shift is the foundation for cost control: fewer hand-built integrations, more reusable components, and a smaller marginal cost to automate the next process step, variant, or exception. Over time, the savings compound because improvements land in shared knowledge artifacts and standardized interfaces, not in scattered scripts that have to be rediscovered and reworked.
It also matters because APA is built for speed and agility. Markets, regulations, products, and internal policies change continuously; the organizations that win are the ones that can adapt without pausing to rebuild their automation stack. With APA, change can be absorbed by updating the governing knowledge—policies, decision criteria, required evidence, and system mappings—so agents can execute the new rules immediately across many processes. The result is faster cycle times for operations and for change itself: teams can launch new products, adjust controls, or expand into new channels with less lead time, because the execution layer is designed to recompile context and behavior as standards and knowledge evolve.
Conclusion
Agentic Process Automation reframes enterprise automation around the hard part of real work: the whitespace between SaaS platforms, the messy middle where inputs are incomplete, records disagree, policies are contextual, and exceptions are normal. What is clear is that the next gains in business process automation will come less from drawing better workflows and more from embedding agents directly into business processes where judgment is executed, constrained, and audited.
That shift changes what “automation” means in an enterprise: from brittle RPA/BPA tools and scripts that follow a predefined route to Agentic Process Automation where agents can plan within guardrails, gather the right evidence, ask for what’s missing, and escalate only when policy requires it—leaving an audit-ready trail either way. Agentic Process automation is a new control surface for process execution, one that treats ambiguity as a design input and makes exception handling measurable, governable, and improvable.
***
This article was written in collaboration with John Miller. Feel free to reach out and connect with the authors - Eric Broda and John Miller on LinkedIn or respond to this article. Questions and comments are welcome and encouraged!
If you liked this article, then you may be interested in a few more things...
Looking for more?
👉 Discover the full O’Reilly Agentic Mesh book by Eric Broda and Davis Broda🎧 Follow co-hosts John Miller and Eric Broda on The Agentic Mesh Podcast on Youtube, Spotify and Apple Podcasts. A new video every week!
***
All images in this document except where otherwise noted have been created by Eric Broda. All icons used in the images are stock PowerPoint icons and/or are free from copyrights.
The opinions expressed in this article are that of the authors alone and do not necessarily reflect the views of our clients.
 | A guest post by
|
I first learned about Agentic AI, the Agentic Process Automation, and Agentic Mesh by reading Eric Broda's articles, and wrote about them in a couple of my blogs at irvingwb.com. I look forward to continuing to learn about Agentic AI from Eric both in the new book he co-authored and in his Agentic Mesh Substack.